Audience Prediction Project Using Big Data Analysis
Movie Audience Prediction Project through Big Data
I-GPS Practical Problem Research Group
March 1, 2019 - November 22, 2019
Background:
In movie production, various decisions such as distribution and scheduling are made based on analyzing and predicting a film’s box office performance. As the movie industry continues to grow, accurately predicting box office success has become increasingly important. This project was initiated to quantitatively forecast individual movie audience demand.
The project has been ongoing for two years, and I participated in 2019. In 2018, the focus was on developing a model to predict weekly audience demand for individual films. In 2019, we aimed to create a more sophisticated daily prediction model.
Approach:
To achieve this, we incorporated 9 movie-related features, including genre, nationality, rating, season, holidays, event day, actor, director, and distributor power.
We also utilized sentiment scores derived from Naver movie reviews to account for the online effect.
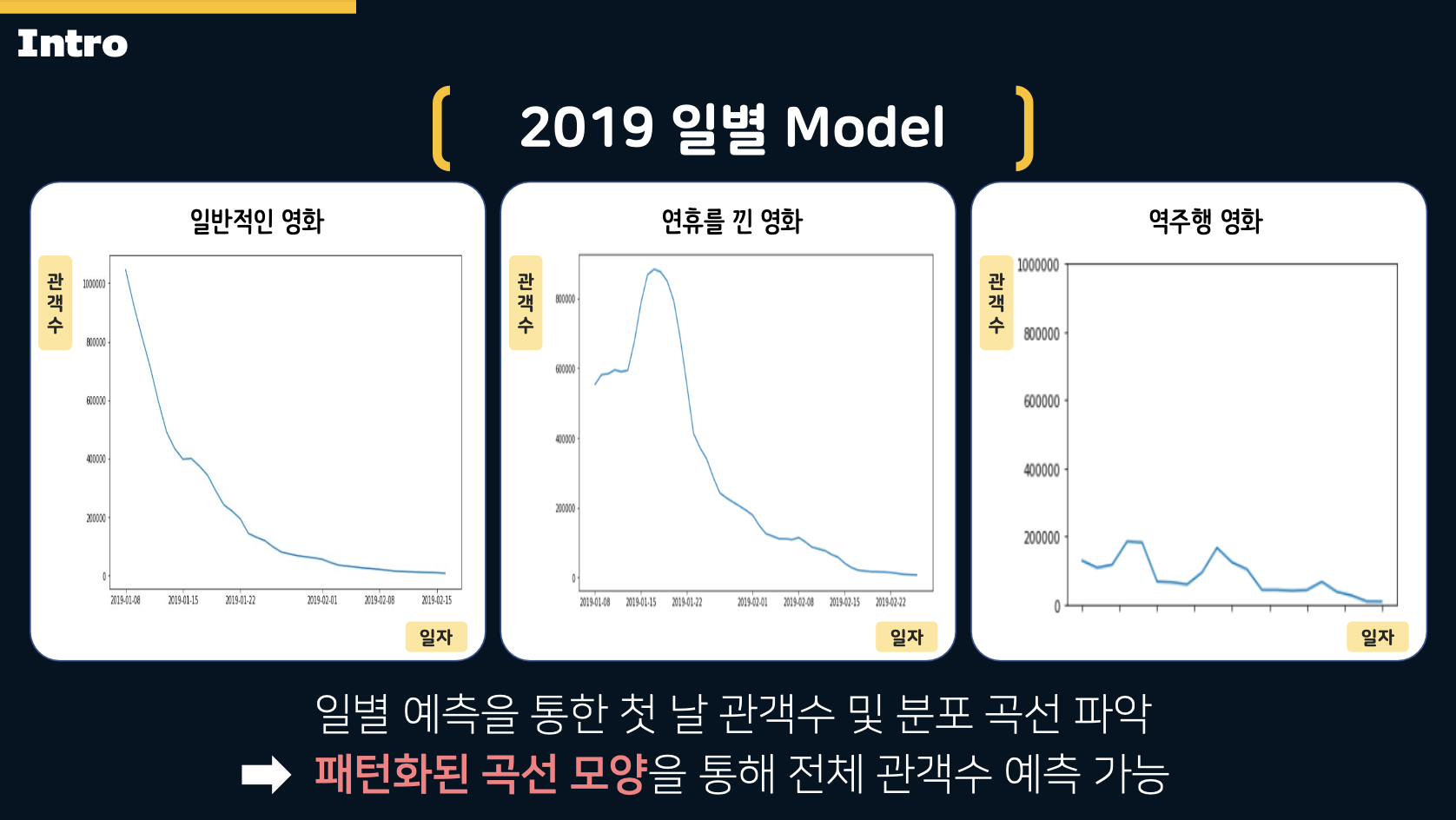
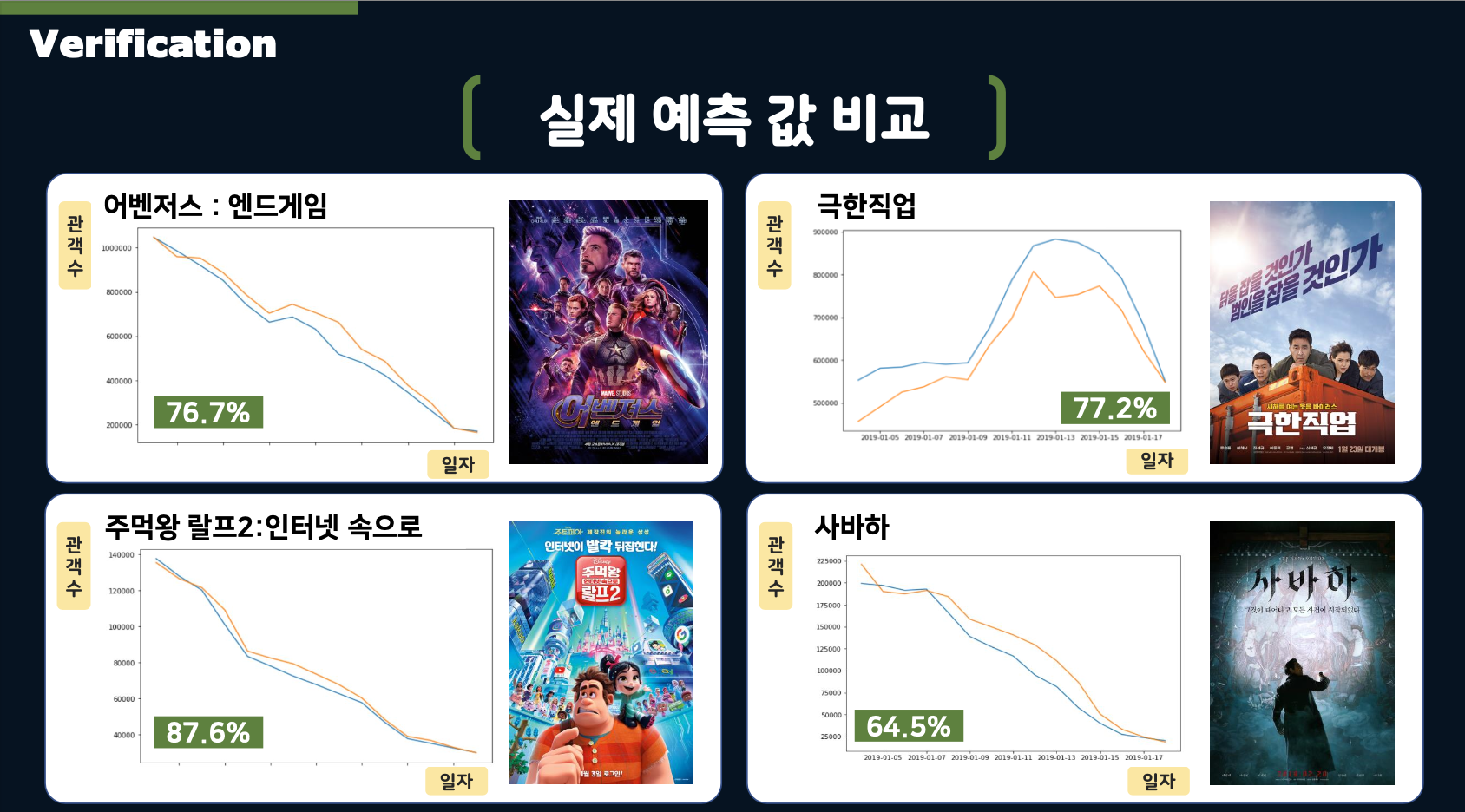
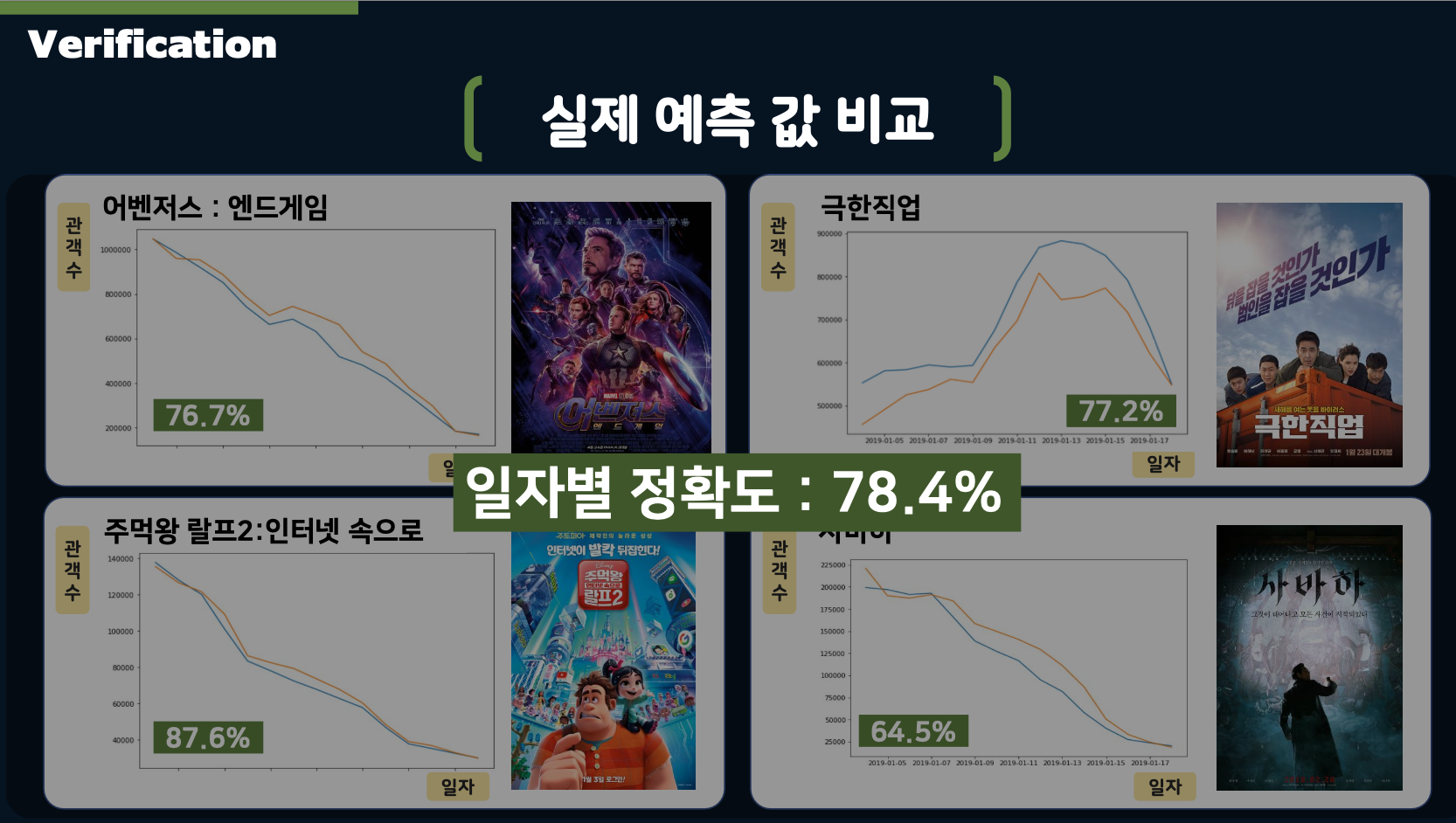
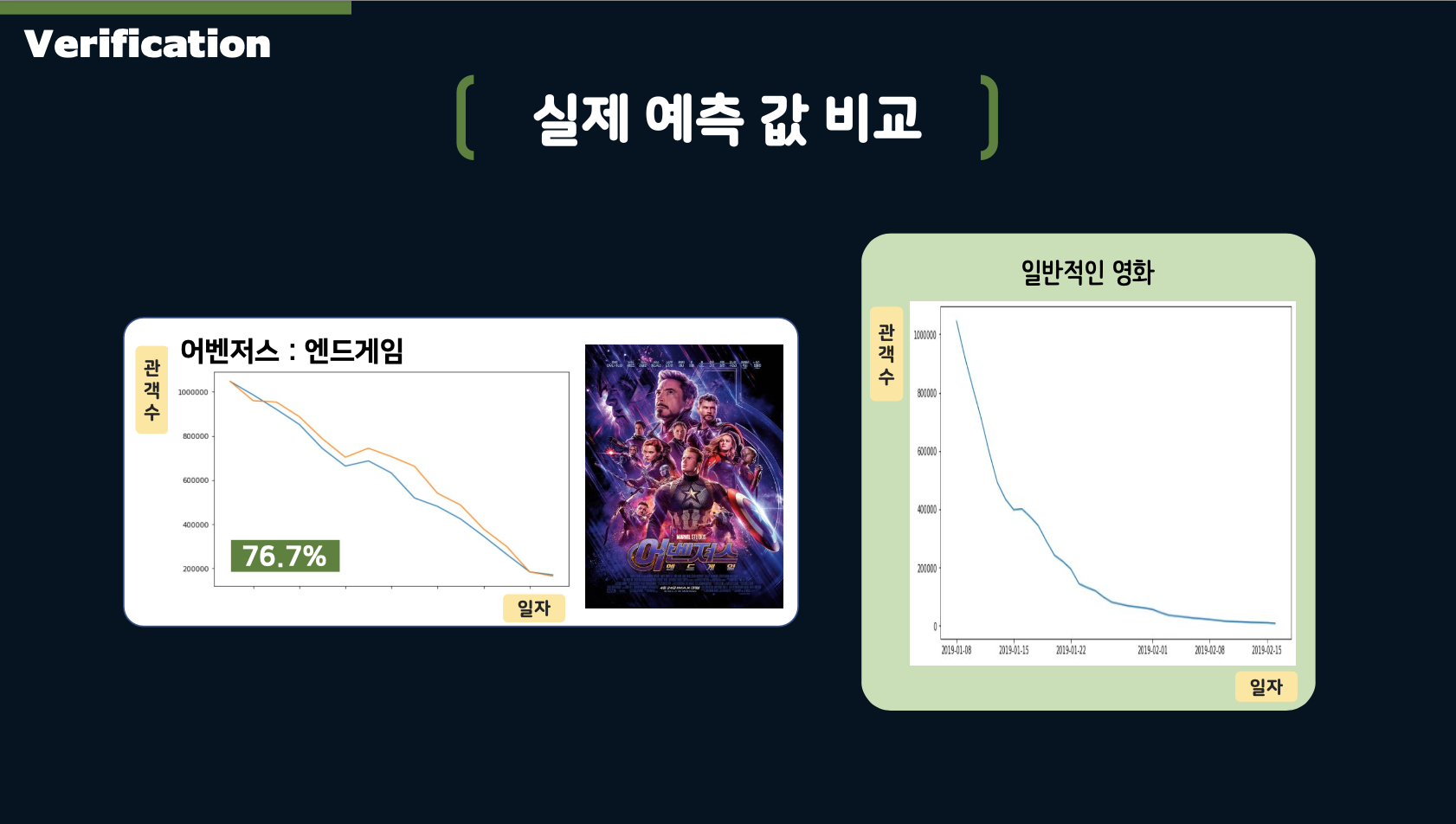
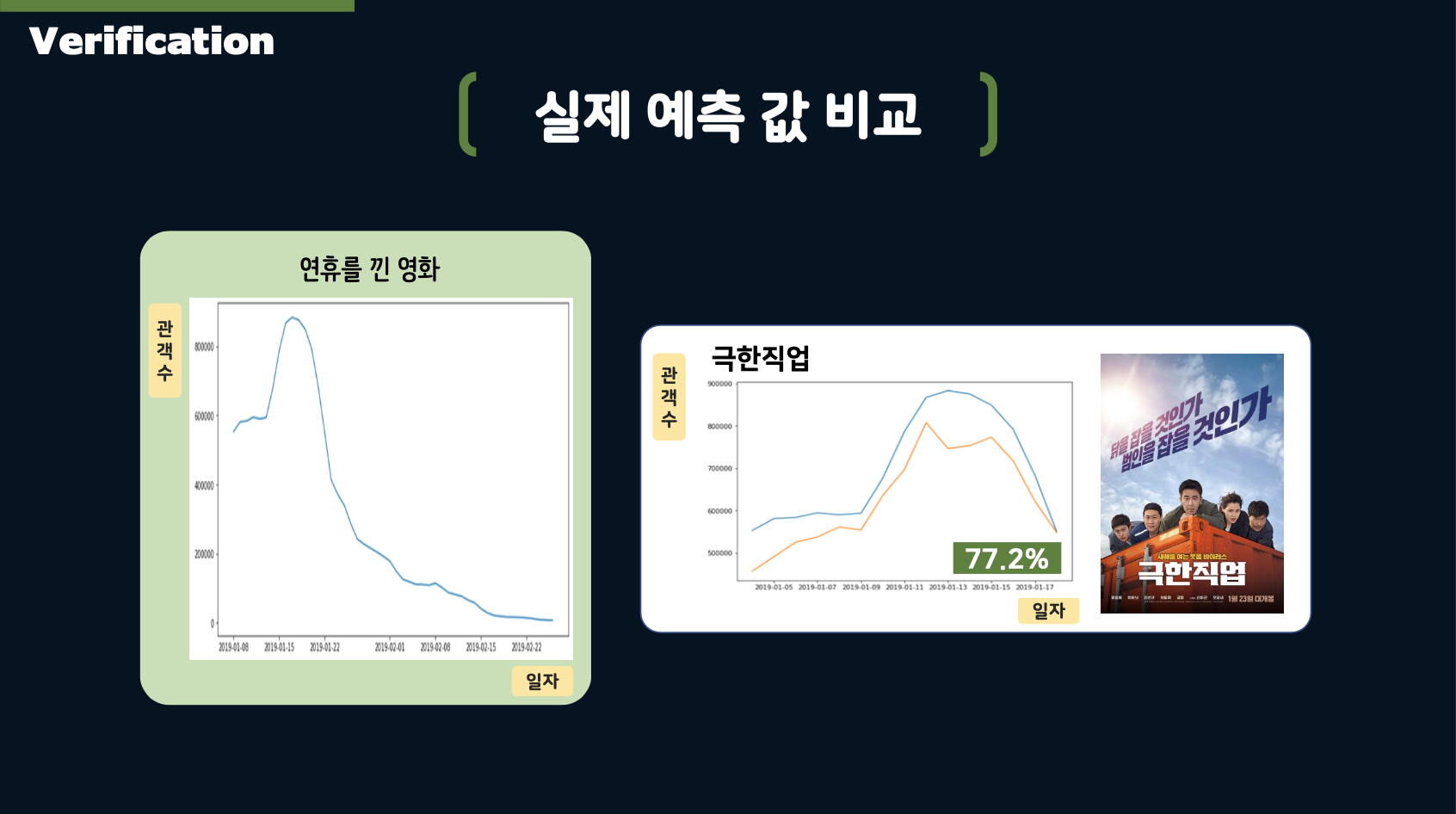
- The above slide illustrates the Protect architecture. Additionally, we applied patterned curves for predictions by classifying movies into three categories: General films, films released around holidays, and rebounding films.
This allowed us to predict daily audience numbers by identifying the opening day audience and curves, using these patterned curves to estimate the total audience.
Prediction Models
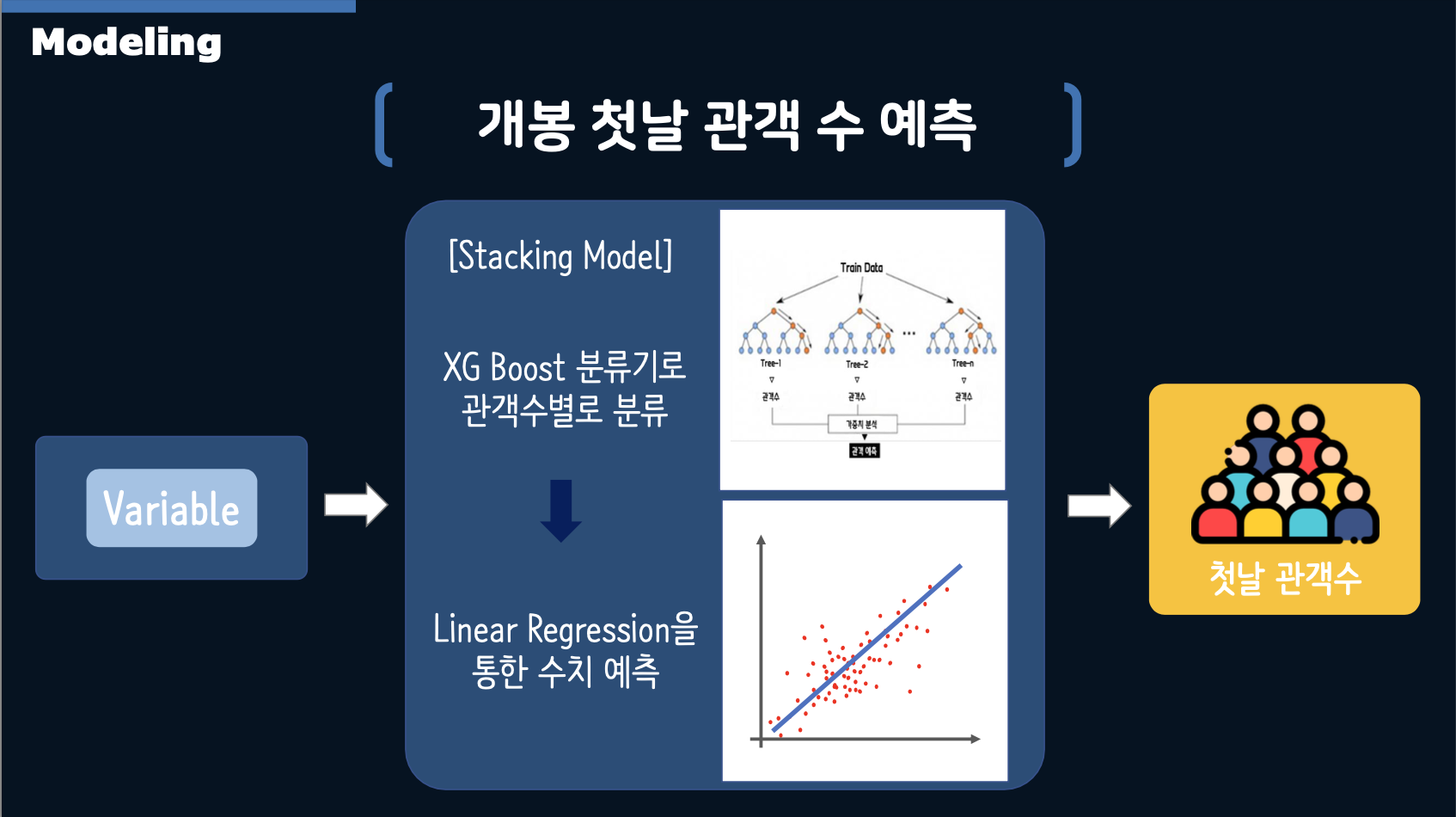
- For predicting the opening day audience count, we used XGBoost to classify audience numbers and then applied Linear Regression for numerical prediction.
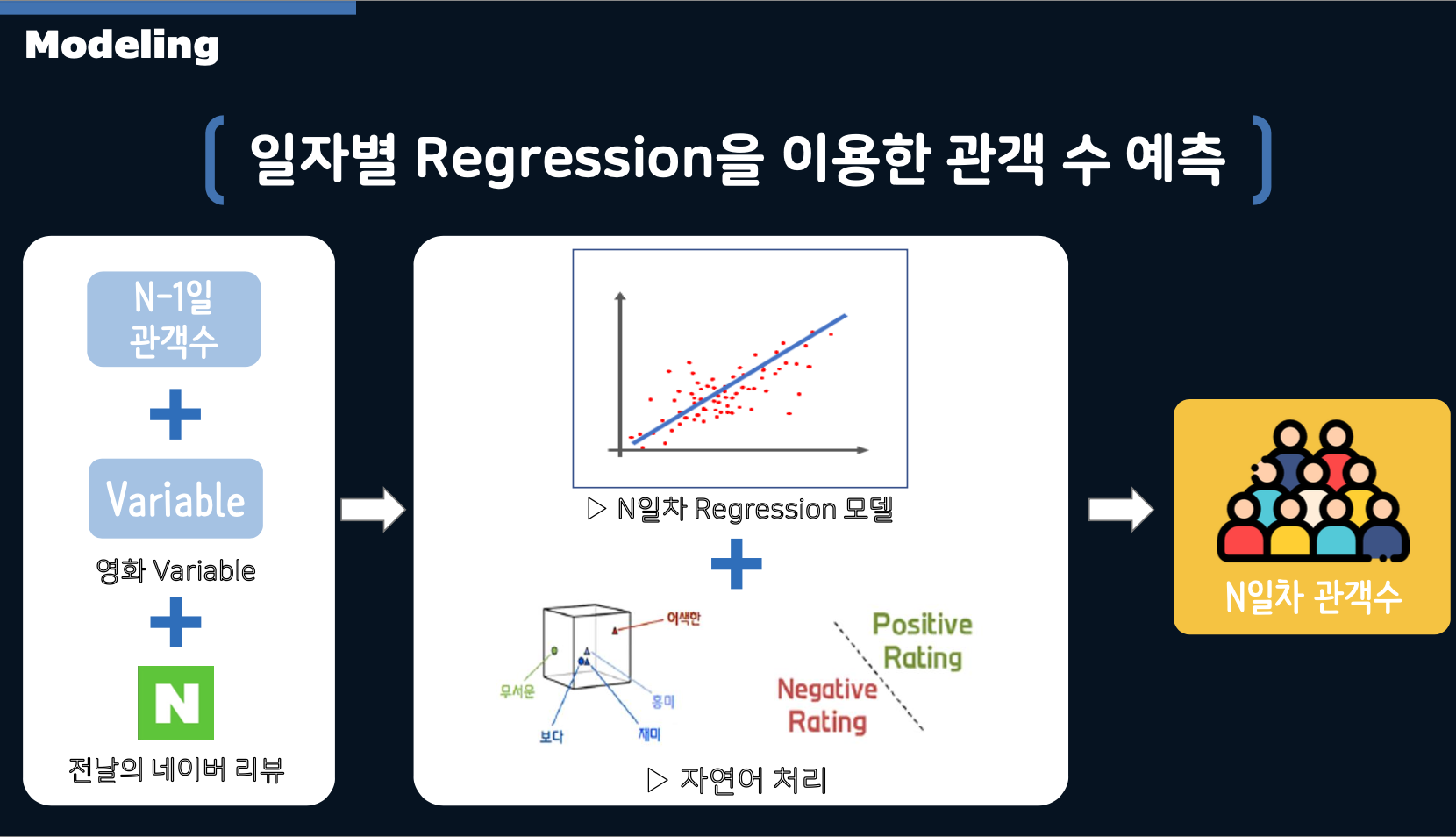
- The daily audience predictions were made using: variables, n-1 day’s audience numbers and n-1 day’s sentiment scores derived from Naver reviews.
My role was to develop a crawler that gathered reviews for films with over 100,000 viewers from 2015 to 2019, providing the data in an analyzable format.
- Web Scraping: Implemented a web crawler to collect and preprocess movie reviews data.
- Data Preparation: Converted raw review data into a structured dataset suitable for analysis.
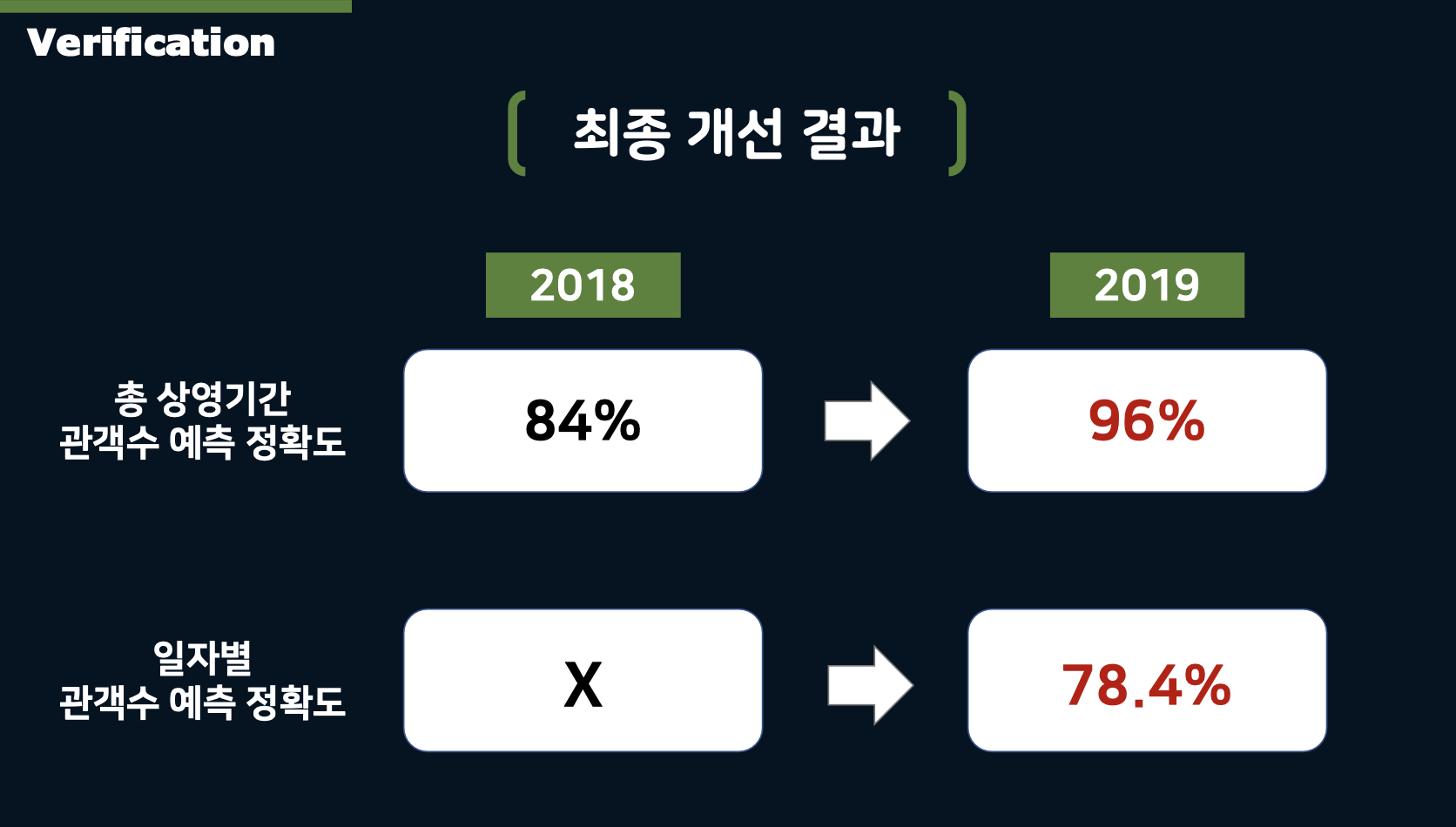
Results: